


Introduction.
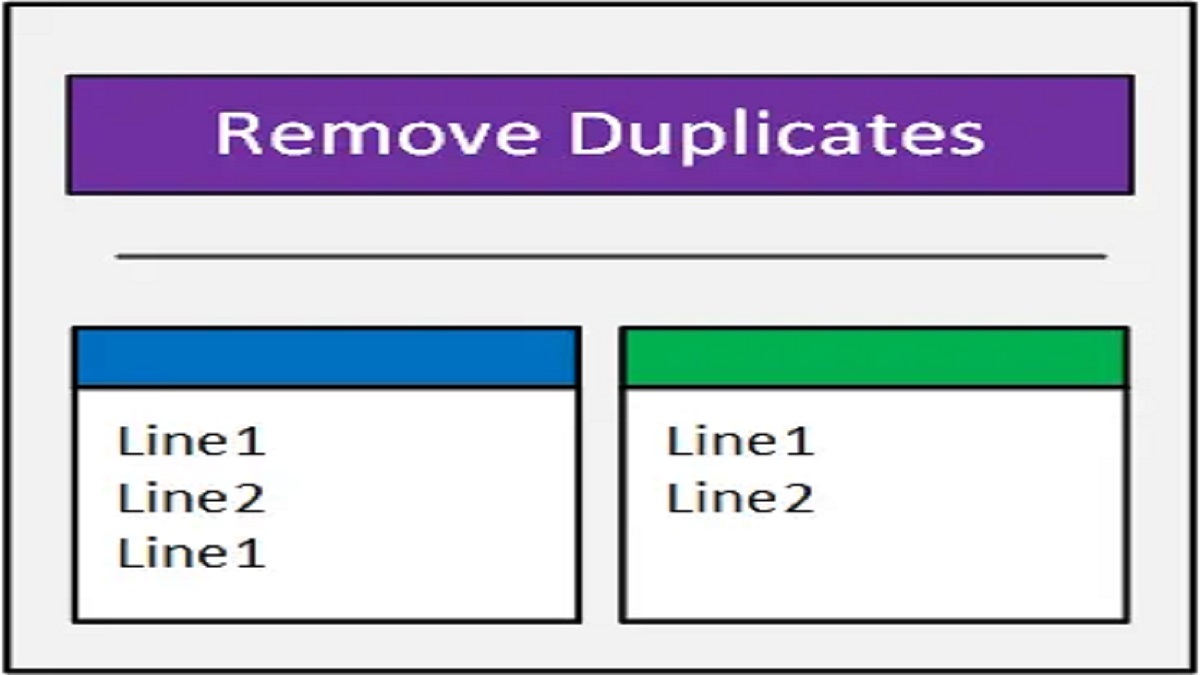
Duplicate Lines Remover: In the world of data processing and analysis, ensuring data accuracy and cleanliness is paramount. Duplicate lines within datasets can skew analysis results, distort insights, and impede decision-making processes. Enter the Duplicate Lines Remover, a versatile tool designed to detect and eliminate duplicate lines from datasets efficiently. In this comprehensive guide, we delve into the intricacies of Duplicate Lines Remover, exploring its functionalities, significance, and practical applications in the realm of data management and analysis.
Understanding the Impact of Duplicate Lines.
Before delving into the nuances of Duplicate Lines Remover, it’s essential to understand the significance of duplicate lines within datasets. Duplicate lines refer to identical or nearly identical rows of data that appear more than once within a dataset. These duplicates can arise due to various factors, including data entry errors, system glitches, or inconsistencies in data integration processes.
The presence of duplicate lines can have several implications:
1. Data Accuracy: Duplicate lines can lead to inaccuracies in data analysis, as they inflate counts, skew averages, and distort statistical distributions. Analyzing datasets with duplicate lines may yield misleading results and compromise the integrity of analytical findings.
2. Data Storage: Duplicate lines contribute to data redundancy and bloat, increasing storage requirements and resource consumption. Large datasets with numerous duplicate lines consume unnecessary disk space and memory, impacting system performance and scalability.
3. Data Integrity: Duplicate lines can undermine data integrity and quality, making it challenging to maintain a single source of truth. Inconsistent data across duplicate entries may lead to discrepancies in reporting, decision-making, and regulatory compliance efforts.
4. Data Processing Efficiency: Processing datasets with duplicate lines requires additional computational resources and processing time. Identifying and removing duplicate lines streamlines data processing workflows, enabling faster analysis, and more efficient resource utilization.
Introducing Duplicate Lines Remover: Streamlining Data Cleanup.
Duplicate Lines Remover emerges as a valuable tool for data analysts, data scientists, and database administrators seeking to streamline data cleanup processes and ensure data integrity. Equipped with advanced algorithms and user-friendly interfaces, Duplicate Lines Remover offers a range of functionalities tailored to meet the diverse needs of users.
Key features of Duplicate Lines Remover include:
1. Duplicate Detection: Duplicate Lines Remover employs sophisticated algorithms to detect duplicate lines within datasets accurately. By comparing data values across rows or columns, the tool identifies identical or nearly identical entries and flags them for removal.
2. Customizable Deduplication Criteria: Users can define customizable criteria for duplicate detection, including specific columns or fields to consider, tolerance thresholds for similarity comparisons, and exclusion rules for certain data subsets. This flexibility enables users to tailor deduplication processes to their unique data requirements.
3. Automatic or Manual Removal: Duplicate Lines Remover offers options for automatic or manual removal of duplicate lines, depending on user preferences and data complexity. Automatic removal modes apply predefined deduplication rules and thresholds, while manual removal modes allow users to review and confirm duplicate removal decisions.
4. Preview and Validation: The tool provides preview and validation features to enable users to review duplicate detection results before applying removal actions. Preview functionality displays identified duplicate lines for review, while validation checks ensure data integrity and consistency post-deduplication.
5. Batch Processing Support: Duplicate Lines Remover supports batch processing of datasets, allowing users to deduplicate large volumes of data efficiently. Batch processing capabilities enable users to process multiple datasets simultaneously, enhancing productivity and scalability.
Significance and Practical Applications of Duplicate Lines Remover.
The significance of Duplicate Lines Remover extends across various industries and domains, with practical applications including:
1. Data Analysis and Reporting: Duplicate Lines Eraser facilitates accurate and reliable data analysis by ensuring that datasets are free from duplicate entries. Analysts and researchers can trust the integrity of their findings, make informed decisions, and generate insightful reports based on clean and deduplicated data.
2. Database Management: Database administrators use Duplicate Lines Eraser to maintain data quality and consistency within databases. By periodically deduplicating database tables, administrators ensure that data remains accurate, up-to-date, and optimized for efficient query processing.
3. Data Migration and Integration: During data migration and integration projects, Duplicate Lines Eraser helps streamline the consolidation and cleanup of disparate datasets.
4. Customer Relationship Management (CRM): CRM systems rely on clean and deduplicated data to drive effective customer engagement and relationship management initiatives.
5. Compliance and Regulatory Reporting: In regulated industries such as finance, healthcare, and government, data accuracy and integrity are critical for compliance and regulatory reporting. Duplicate Lines Eraser supports compliance efforts by ensuring that datasets meet quality standards and adhere to regulatory requirements.
Challenges and Considerations in Duplicate Lines Removal.
While Duplicate Lines Remover offers valuable capabilities for data cleanup, several challenges and considerations merit attention:
1. Data Complexity: Datasets with complex structures, nested data, or unstructured text may pose challenges for accurate duplicate detection and removal. Advanced data parsing and similarity comparison techniques may be required to address these complexities effectively.
2. Performance Optimization: Processing large datasets with millions of rows or complex data types may impact the performance and responsiveness of Duplicate Lines Remover. Optimization strategies such as parallel processing, memory management, and algorithmic efficiency enhancements can mitigate performance bottlenecks.
3. Data Privacy and Security: Duplicate Lines Eraser must adhere to data privacy and security standards to safeguard sensitive information during deduplication processes.
4. Error Handling and Recovery: Handling errors and exceptions that arise during duplicate removal operations is crucial for maintaining data integrity and continuity.
5. User Training and Adoption: Effective utilization of Duplicate Lines Eraser requires adequate user training and adoption within organizations.
Conclusion.
In the era of big data and data-driven decision-making, Duplicate Lines Eraser emerges as a fundamental tool for ensuring data accuracy, integrity, and cleanliness. As organizations continue to prioritize data quality and reliability, Duplicate Lines Remover stands as an indispensable asset in the data management toolkit, empowering users to unlock actionable insights, derive meaningful conclusions, and drive innovation in the digital age
Visit Proweblook for more Web API tools. More resources can be found on our Github page, Social Channels are Twitter, Facebook & Youtube.



